Project: K.N.S. AddressBook
K.N.S. AddressBook is a Java desktop address book application created by Team W11-B3 during the course of CS2103T Software Engineering in AY2017/8 Semester 1. This Portfolio details my major contributions to the project, and lists our other minor contributions as well.
Code Contributed: [Functional Code] [Test Code]
Enhancement Added: Partial Finding
Partial Matching
The Find command accepts partial matches by default.
Keywords will match entries if they are contained within those entries.
| However, vice-versa does not apply! i.e. Entries will not match keywords if the entries are contained within the keywords. |
Examples:
-
find mel
MatchesMelissaandAmelia -
find amelia
MatchesAmeliabut notMelissaorMel -
find leon
MatchesLeonardbut notLeo -
find t/ frien
Matches any person with a tag that containsfrien, e.g.FriendsorBestFriends
End of Extract
Justification
Most people will likely not fully remember their contact details, so a partial find of some kind would be very beneficial to have in the find command. Even if they do, a partial find can still be useful in reducing the actual number of characters someone has to type, because they can type the keywords up to a point where they’re sure that it won’t match most contacts other than the one they’re looking for. So, given that partial finding is more convenient for everyone, I decided that it was more appropriate than exclusive matching.
Partial Find
The partial matching of the Find command is implemented by creating a method in the StringUtil class with the help of
the regionMatches method from the java String class.
It replaces the method for matching in all predicate classes that is used by the command.
| The Find command now only use partial matching and has lost the full matching functionality |
Previously, the method used for matching was implemented as such:
public static boolean containsWordIgnoreCase(String sentence, String word) {
// ...check and prepare arguments..
for (String wordInSentence: wordsInPreppedSentence) {
if (wordInSentence.equalsIgnoreCase(preppedWord)) {
return true;
}
}
return false;
}By using the equalsIgnoreCase method, the query word has to exactly match, ignoring case, the sentence word for the
method to return true.
A slightly modified version of the previous method is created to allow for partial matching as such:
public static boolean containsWordPartialIgnoreCase(String sentence, String word) {
//..check and prepare arguments..
return preppedSentence.contains(preppedWord);
}By using the contains method, the query word can now be a substring of the sentence word.
It also shortens the method, as there is no more need to check through word-by-word.
Afterwards, the use of the previous method in the Predicate classes in model
(e.g. NameContainsKeywordsPredicate) is replaced with the new method so that the Find command actually uses partial matching.
Design Considerations
Aspect: Exclusive use of partial matching.
Alternative 1 (current choice): Find command exclusively uses partial matching.
Pros: Simple implementation, doesn’t affect complexity from user’s perspective and easier for users to utilize Find
command.
Cons: Users lose the ability to do full matching when it would be useful
(e.g. a lot of people with similiar names).
Alternative 2: Give the option to toggle/use either partial matching or full matching
Pros: More flexible and powerful.
Cons: Requires more complicated syntax which can be confusing to new users, most use cases are already covered by
partial matching.
Aspect: Type of partial matching
Alternative 1 (current choice): Matches can be from anywhere in the word
Pros: More intuitive way of searching, simpler to understand.
Cons: Search results become less relevant for short keywords. (Mitigated by sorting the results based on match position)
Alternative 2: Matches are required to be from the start of each word.
Pros: Restricts the scope of search which increases relevancy but still giving enough flexibility for users.
Cons: Can be unintuitive, less powerful.
End of Extract
Enhancement Added: Find by Tag
By Tag
To find by tag, you can use the prefix t/.
| When finding by tag, it will match person with any tag matching at least one of the keywords. |
Examples:
-
find t/ family
Returns any person with the tagfamily -
f t/ friends family colleague
Returns any person with at least one of the tagsfriends,family, orcolleague.
End of Extract
Justification
Similar with partial finding, there will be times where the name is the field that is forgotten by the user. In such
scenarios, without the ability to find by tags (or other fields), the user’s capability to locate a person will be
crippled, and alongside it, the usefulness of our application. So, I decided that a find by tag was necessary. The tag
prefix is used to indicate searching by tag as the user would be most familiar with it already, given that other
commands, such as add and edit, already uses such a format.
Find by All Field
The find by all field feature is implemented by adding one argument, prefix of field that want to be searched, to the
find command parameter. If the user does not specify the prefix, the address book will automatically search the query
in the name field. The FindCommandParser will parse the input given by the user. The mechanism to find by each field is
implemented in <field name>ContainsKeywordPredicate class (i.e. NameContainsKeywordPredicate,
AddressContainsKeywordPredicate) inside Model component.
Java Implementation
The FindCommandParser is now able to parse the additional prefix argument, as shown in the code snippet below:
public FindCommand parse(String args) throws ParseException {
// make sure that the argument is valid
// store the prefix inside String 'toSearch'
// store the search query inside array of string 'keyword'
if (toSearch.equals(PREFIX_TAG.getPrefix())) {
return new FindCommand(new TagListContainsKeywordsPredicate(Arrays.asList(keywords)));
} else if (toSearch.equals(PREFIX_PHONE.getPrefix())) {
return new FindCommand(new PhoneContainsKeywordsPredicate(Arrays.asList(keywords)));
} else if (toSearch.equals(PREFIX_EMAIL.getPrefix())) {
return new FindCommand(new EmailContainsKeywordsPredicate(Arrays.asList(keywords)));
} else if (toSearch.equals(PREFIX_ADDRESS.getPrefix())) {
return new FindCommand(new AddressContainsKeywordsPredicate(Arrays.asList(keywords)));
} else if (toSearch.equals(PREFIX_BIRTHDAY.getPrefix())) {
return new FindCommand(new BirthdayContainsKeywordsPredicate(Arrays.asList(keywords)));
} else {
return new FindCommand(new NameContainsKeywordsPredicate(Arrays.asList(keywords)));
}
}After FindCommandParser parse the arguments, it will call the <field name>ContainsKeywordsPredicate class for each respective field.
All contacts with partial matches will appear on the search result, implemented in the method below for phone field. The method is similar for other field.
public boolean test(ReadOnlyPerson person) {
return keywords.stream().anyMatch(keyword -> StringUtil
.containsWordPartialIgnoreCase(person.getPhone().value, keyword));
}Design Considerations
Aspect: Implementation of find by all field
Alternative 1 (current choice): Enables user to find by all field (name, phone, email, address, birthday, and
tag).
Pros: Easier for user to find their contacts when the user does not remember their contact’s name, instead they
remember the contacts' details (such as address or birthday). This feature is useful for a broader range of purpose,
for example when the user wants to send a birthday wishes to their contacts, the user can easily find by using
birthday field.
Cons: Need to type the prefix of the field that want to be searched.
Alternative 2: Find by name only.
Pros: Some people only remember their contact’s name, and find by all field feature might not be useful for them as
they don’t remember their contact’s details.
Cons: User could not find their contact details when they do not remember their contact’s name.
Aspect: Find result upon executing find command.
Alternative 1 (current choice): All contacts with partial match with the find query will appear.
Pros: With less restrictive requirement, users can find a broad range of contacts when they are searching using a
global keyword. For example, a user can find all their contacts who lived in "Clementi" when using this alternative.
Cons: More contacts will appear on the find result, some of them might not be the target contact that the user
wants to find.
Alternative 2: Only contacts with exact match will appear.
Pros: Less contacts will appear on the find result, easier to find the exact person while searching for a single
person.
Cons: It will be hard for a forgetful user to find their contacts as they may remember their contact details'
partially. This alternative is also more cumbersome when applied to find by address, as user need to type the full
address of their contact.
End of Extract
Enhancement Added : Sorting
External Behavior
Find Auto-sort
Start of Extract [from: User Guide]
When finding by name, the result will auto sort according to the position of the match. e.g. find Bo will list Bo Alex before Holbo and Holbo before Alexander Bo
|
End of Extract
Sort Command
Start of Extract [from: User Guide]
Sorting your contact list: sort
If you want to view your current list in a better way, you can use the sort command to
sort the current list lexicographically by the given prefix, in the given order.
To sort the current list, you can use: sort [PREFIX] [ORDER]
Examples:
-
list
sort des
Sorts the list in reverse order of insertion (i.e. the previous list is now reversed) -
find t/ friends
sort n/
Sorts the resulting list from thefindcommand by name, in ascending order.
(i.e. the list is now a list of people who has a tag matching friends, sorted alphabetically by name.)
End of Extract
Justification
With the target audience in mind, I thought it was likely that there would sometimes be a scenario where the user wants
to view a relatively large find result. Given so, I decided to implement 2 kinds of sorting, one integrated into the find
command, and the other as a sort command, in order to maximize the ease at which the user can parse through the result
list. The Auto-Sort integrated into the find command will help users who wants to search for a person, but only remember a short
part of their name. The sort command will help users who want to organize their search results, in order to record them
for other purposes.
Sorting viewable list
The sort command and auto-sorting of the find command is facilitated by a SortedFilteredList inside the ModelManager class. This list is created on top of
the FilteredList that is used to filter the contact list. A Comparator called defaultSortOrder was also created to as a
comparator to reset the sorted list to its default order. ModelManager was also modified to support updating the sorted list only,
and to always reset to default order whenever the filtered list is updated.
Commands that changes the viewable list without any sorting are implemented as:
public class ListCommand extends Command {
@Override
public CommandResult execure() {
// ... some logic ...
model.updateFilteredList(some predicate);
// ... more logic ...
}Whereas commands with sorting (e.g. find) is implemented as:
public class FindCommand extends Command {
@Override
public CommandResult execute() {
// ... some logic ...
model.updateFilteredList(some predicate);
model.updateSortedFilteredList(some comparator);
// ... more logic ...
}Auto-Sort of Find Command
The find command, when matching by name, sorts its resulting list by the earliest position of a match with a given keyword.
This is implemented by creating a earliestIndexOf method in the StringUtil class, which takes in a sentence and a list of keywords, and returns the earliest starting index where a part of the sentence matches a keyword, or -1 if there are no match.
As an example, suppose the address book contains three people:

Figure 5.5.1.1: 3 People Listed in the PersonList
When a find n/ i command is executed, it will match all three of them (since all their names contains i),
and show them in this order:

Figure 5.5.1.1: 3 People Listed in the New Order
as Michael has i in the 2nd position, Alicia has an i in the 3rd position, and Daniel has an i in the 4th position.
Design Considerations
Aspect: Implementation of sorting
Alternative 1 (current choice): Sort the viewable list only by creating a SortedFilteredList
Pros: Preserves the original order without additional changes, sort without worrying about changing the data.
Cons: Harder to implement a permanent sort functionality.
Alternative 2: Sort the data directly
Pros: Easier to make a permanent sort.
Cons: Cannot go back to original order without additional changes. Harder to sort temporarily.
Aspect: Type of sorting in find
Alternative 1 (current choice): Sort the resulting list of find by the earliest matching index.
Pros: Make searching with short keywords more effective since the desired result is likely at the top.
Cons: Can be unintuitive, especially since it’s only done when finding by name.
Alternative 2: Show the resulting list in the default sort order.
Pros: More intuitive. No need for extra code.
Cons: Harder to find desired person when the result list is long.
Aspect: Mechanism to create comparators
Alternative 1 (current choice): sort and find uses separate method to create Comparator
Pros: More flexible since each command can do a different kind of sorting.
Cons: A lot of similar logic is copied to implement the methods individually.
Alternative 2: Create a class or method that returns Comparators.
Pros: Only implement once. Each sorting method now just need to call this method.
Cons: Take longer to code. Need to allow access to private variables in predicate classes.
End of Extract
Saving/Backing up your data: export or ex
Exports current address book data to a file with the specified filename in the data folder.
While K.N.S provides automatic data saving, you can still manually back up your data using the export command.
To export your data, you should type:
export or ex FILENAME.xml
where FILENAME is the name you want to give to the exported data.
This will export your current address book data into a file with the specified filename.
Exported data is saved in the data folder, which should be in the same folder as the application file, by default.
|
If a file with the filename you entered already exists in the data folder, it will be overwritten without warning!
|
Examples:
-
export backup.xml
Exports your data in thedatafolder asbackup.xml -
ex copy
Fails and will prompt you to add a.xmlto the end of the file name.
Importing data: import or i
Imports data from the file in the given filepath, and overwrite current address book data.
To import data from another application or your own backup data, you can use the import command with the format:
import or i FILEPATH
where FILEPATH is the relative filepath of the data to be imported. (Usually in the data folder)
The data file to be imported does not have to be a .xml file, as long as the its contents are correctly formatted.
|
|
When you import data, you cannot get your old data back once you close the application. (you can still use undo if you haven’t)It is recommended to backup using the export command first before importing.
|
Examples:
-
import data/backup.xml
Imports the data in the filebackup.xmlin thedatafolder which should be located in the same folder as the application. -
i copy
Imports the data in the filecopywhich should be located at the same folder as the application.
End of Extract
Justification
As the application provides automatic saving, I thought it was prudent to have a manual saving mechanism, in order for
users to defend against accidents that the undo/redo mechanism can’t fix, such as accidentally closing the application
without realizing a mistaken delete. It also provides a way for less savvy users who does not know how to manually back
up and import their data to do so.
Keeping that in mind, the current behavior mainly supports backing up your data and
loading them afterwards, instead of being able to switch your address book to work on another one, since that is not the
intended purpose.
Import & Export Mechanism
The import and export mechanism is implemented using the XmlAddressBookStorage class. It allows for the manual saving and loading of the
address book data, aside from the default initial loading and automatic saving, by using the export and import command.
Import only changes the address book’s data, and does not change the user preference. Notably, it does not change
the default file which the application automatically saves to, which is addressbook.xml. Instead, it overwrites the current data with
the data in the given filepath, provided it is a valid address book data.
The following shows the dependencies of both ImportCommand and ExportCommand:
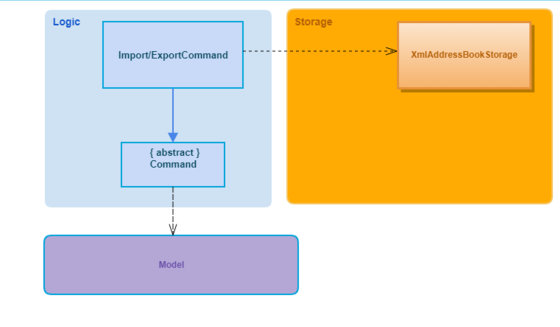
Figure 5.4.1: Import/Export Association Diagram
If the XmlAddressBookStorage fails to read or write to file, an Exception will be thrown.
The same will happen if the file contains persons with illegal values. (e.g. empty name)
|
Suppose the user has just initialized the application, and the data folder is empty.
The user makes some changes to the data (e.g. using clear and add to clear away the sample and add their own contacts) which
saves the data in the data folder as addressbook.xml automatically.
Then, without altering the data any further, the user decides to save a manual backup using a export backup.xml command.
This will create a backup.xml file in the data folder, which at this point is equivalent to the addressbook.xml.
As the user continues to alter the data, the addressbook.xml file will keep changing, and will be different than the backup.xml
file.
The user then decides that they want to return the addressbook to their backup version using a import data/backup.xml command.
This will overwrite the current data with the data in backup.xml, making it once again equivalent to addressbook.xml
Sequence Diagram
The sequence diagram for the command export a.xml is the following:
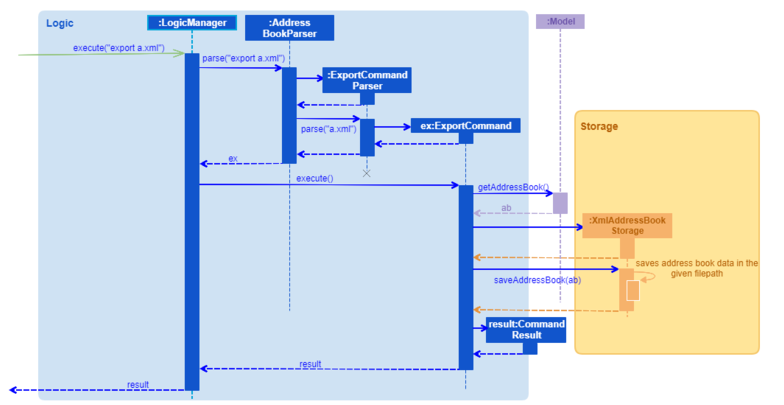
Figure 5.4.1.1: Sequence Diagram for Export Command
An import command would be similar, except that it creates a XmlAddressBookStorage object first, calls the readAddressBook method, and then
calls the resetData method from the Model object.
Design Considerations
Aspect: How import works
Alternative 1(current choice): Overwrite the current address book with the data from the given file.
Pros: Easier implementation, data in the given file is preserved.
Cons: Loses the current address book data, which cannot be recovered if the address book is closed. (Can still be recovered with undo if it has not been closed since the import yet)
Alternative 2: Switch the file that the address book uses to the given file, and save all changes to that file
Pros: Allows for easier use of multiple saved files. The data in the current (before import) file is preserved.
Cons: Harder implementation, does not provide an easy way to import backups, since all changes are saved to the given file.
Aspect: Scope of data to export and import
Alternative 1(current choice): Exports and imports only the address book data, excluding pictures and user preferences.
Pros: Can use the current XmlAddressBookStorage class to read and write. Only read and write a single file.
Cons: Excluding pictures means user have to manually backup pictures, otherwise address book is incomplete (no avatar).
Alternative 2: Include pictures and/or user preferences
Pros: More complete data storage.
Cons: Higher probability of accidentally overwriting files if the user is not careful.
End of Extract
Enhancement Proposed: Boolean Searching
Justification
Given the target audience of our product, it is plausible that they would need to find people who matches certain
criteria without having a specific person in mind. For example, they might need to find everyone who are clients but not
currently overseas. In current form, there is no way for them to do this easily.
Boolean searching will allow them to search using AND and NOT keywords to enable a much easier searching experience.
Other Contributions
-
Modified
addto accept missing prefixes other than name-
Each missing prefix will be shown with a default value to indicate their absence
-
Pull Request : #39
-
-
Set up various project tools, such as :
-
Appveyor and Coveralls configuration for github repo.
-
Github-pages website, via Travis CI.
-
-
Created the table for command cheat sheet in the user guide
-
Pull Request : #63
-